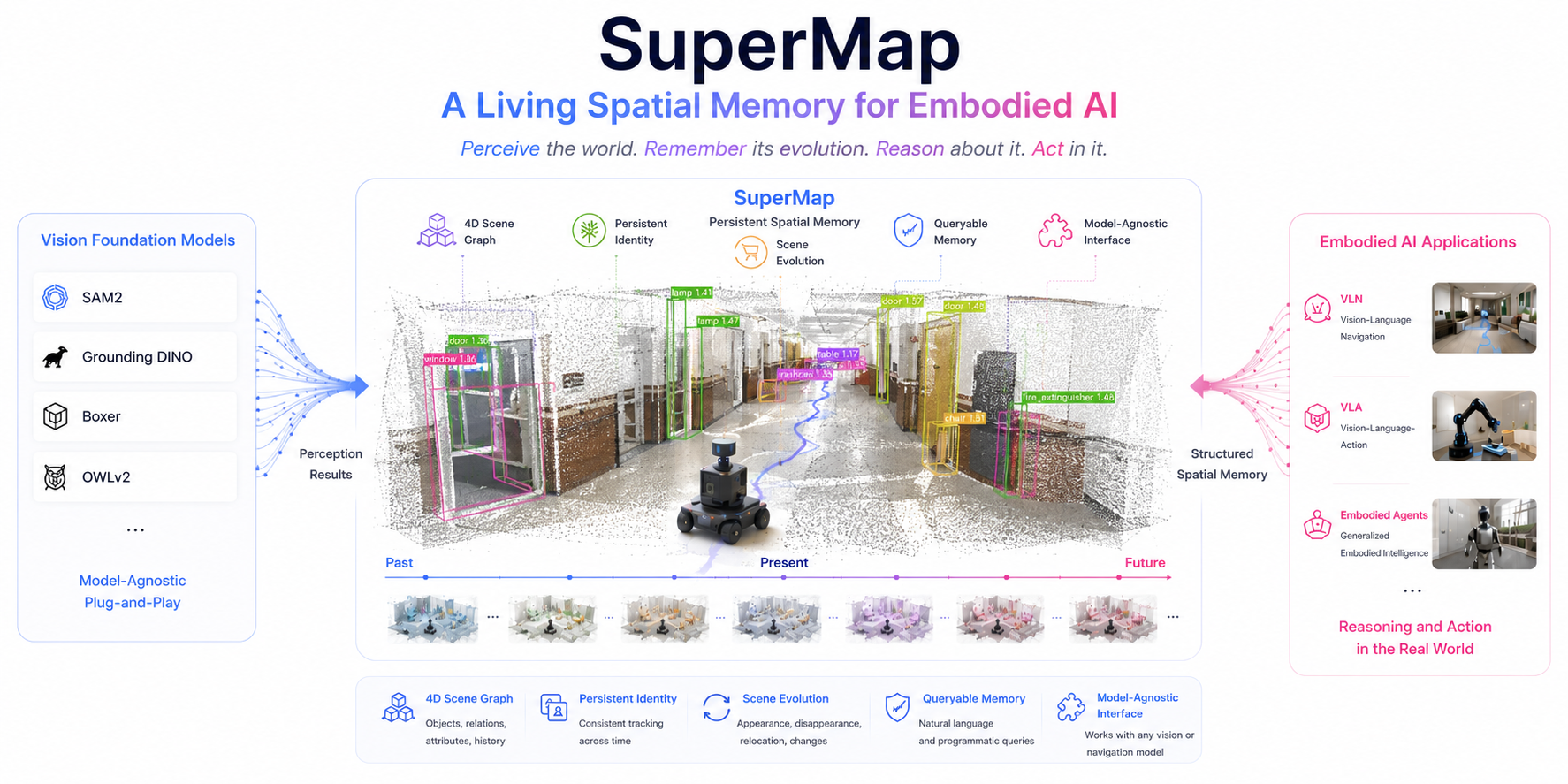
SuperMap
SuperMap: A Spatio-Temporal SLAM System
for Visual-Language Navigation
SuperMap is a living spatial memory for embodied AI — it perceives the world, remembers its evolution, and supports reasoning and action.
”1 · Perception
Perception: Geometric and semantic consistency enable training-free, reliable 3D object mapping.
2 · Memory
Memory: Persistent object identities transform frame-level detections into long-term scene memory.
3 · Reasoning & Action
Reasoning & Action: A structured spatio-temporal memory provides a direct interface for visual-language navigation and embodied reasoning.
4 · Interactive 3D Instance Objects Map — 2 Hour CMU Campus Run from Indoor to Outdoor
Generalization: SuperMap scales to a continuous 2-hour, campus-scale deployment across diverse indoor and outdoor environments without retraining. By maintaining persistent object identities and a temporally consistent semantic map, it transforms geometric mapping into a living spatial memory. This memory enables robots to ground language in 3D space, reason about spatial relationships, remember how scenes evolve over time, and execute visual-language navigation in complex, dynamic environments.
Explore the map: Drag to orbit, scroll to zoom, and right-drag to pan. Hover over a 3D bounding box to view its semantic label, or click to pin it. Hover over a replay card to highlight the robot's trajectory and mapped region, then click to replay the dynamic reconstruction.
Merged 3D Map
Dynamic replays — hover to locate, click to play:
5 · Insight
Insight: SuperMap turns frame-level perception into a persistent, model-agnostic spatial memory — the missing layer between vision foundation models and embodied reasoning.
Persistent Object Tracking
3D-aware instance association plus an existence-and-label confidence update keep object identities stable and prune stale content under occlusion and scene change.
Model-Agnostic Spatial Perception
Rather than replacing foundation models, SuperMap complements them by providing the missing spatial memory — connecting state-of-the-art vision foundation models with downstream embodied agents through a unified, persistent, and structured world representation.
Fully online, open-source
High-frequency geometric SLAM fused with asynchronous open-vocabulary perception runs onboard in real time — released as a deployable baseline.
6 · Abstract
Robotic navigation requires a persistent spatial memory that bridges open-vocabulary perception with long-term scene understanding. While vision foundation models provide strong zero-shot recognition, they operate at the frame level and cannot maintain consistent object identities or reason about scene evolution.
We present SuperMap, a training-free 4D spatio-temporal mapping framework that fuses geometric SLAM with open-vocabulary perception to build a persistent semantic world model. By jointly enforcing geometric and semantic consistency, SuperMap maintains stable object identities, tracks object appearance, disappearance, and relocation, and continuously updates the map as the environment evolves.
The resulting queryable 4D scene graph serves as a unified spatial memory for vision-language navigation and embodied AI, providing a model-agnostic interface between vision foundation models and downstream reasoning and planning systems.
7 · Contributions
Open-Vocabulary Spatio-Temporal SLAM
An online robotic system that builds a persistent, queryable open-vocabulary 4D scene memory suitable for downstream language-conditioned tasks — running fully onboard in real time.
Spatio-Temporal Object Tracking
An online pipeline that integrates 2D–3D association, validation, and change-aware updates to maintain instance consistency under occlusions, partial observations, label variability, and scene change.
Instance-level Scene Graph
A 4D scene graph that incorporates spatial and temporal information for each object, equipping robots with instance-level reasoning — e.g., locating moved objects, recalling past scenes.
Open-Source Framework
Full release of the change-detection benchmark, comprehensive ablations, runtime profiling, and the real-robot visual–language navigation pipeline to facilitate reproducible research.
8 · System Architecture
A three-layer pipeline — geometric, instance, and topological.
Geometric Layer — Online 3D Reconstruction
SuperOdometry provides pose estimation and a colorized dense 3D model from synchronized RGB images, depth/LiDAR, and IMU streams. Geometric priors anchor all subsequent 2D–3D association and global map consistency checks.
Instance Layer — Spatio-Temporal Instance Association
Per-frame open-vocabulary detections (GroundingDINO + SAM2) are associated to existing 3D map objects via a hybrid 2D–3D tracker. A probabilistic geometric consistency update and Bayesian semantic fusion maintain stable object identities across long time horizons under occlusions and scene change.
Topological Layer — Abstract 4D Scene Graph
The object map is abstracted into a scene graph G = (V, Es, Et) with spatial edges (geometric predicates: on, beside, under) and temporal edges (object trajectory history). The graph is serialized as structured text for compositional VLM queries over object semantics, spatial relations, and history.
9 · Results
Class-level Segmentation — ScanNet
SuperMap achieves competitive accuracy against state-of-the-art object-level mapping methods while running fully online.
| Method | Approach | mIoU (%) | f-mIoU (%) | Acc (%) |
|---|---|---|---|---|
| ConceptGraphs | object-level | 21.62 | 24.32 | 31.05 |
| HOV-SG | object-level | 26.79 | 36.05 | 35.17 |
| SuperMap (Ours) | object-level | 27.42 | 43.50 | 55.48 |
Instance-level Segmentation — ScanNet (mAP50)
SuperMap significantly outperforms prior scene-graph methods on instance-level detection.
| Method | Chair | Window | Refrigerator | Sofa | Door |
|---|---|---|---|---|---|
| HOV-SG | 4.58 | 0.00 | 0.00 | 30.00 | 9.70 |
| ConceptGraphs | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| SuperMap (Ours) | 63.76 | 42.20 | 62.50 | 33.35 | 10.00 |
Spatio-Temporal Change Detection Recall
SuperMap achieves perfect recall on appearance events and strong recall on disappearance events, significantly outperforming prior methods.
| Method | Appeared (Bucket) | Appeared (Cart) | Appeared (Sign) | Disappeared (Plant) | Disappeared (Trash) | Disappeared (Chair) |
|---|---|---|---|---|---|---|
| Khronos | — | — | — | — | — | — |
| DualMap | 0.000 | 0.000 | 0.000 | 0.310 | 0.000 | 0.000 |
| SuperMap (Ours) | 1.000 | 0.262 | 0.583 | 0.755 | 0.434 | 1.000 |
10 · Citation
@inproceedings{zhao2026supermap,
title = {SuperMap: A Spatio-Temporal SLAM System for Visual-Language Navigation},
author = {Zhao, Shibo and Chen, Guofei and Zhu, Honghao and Li, Zhiheng and Yao, Changwei and Zantout, Nader and Kim, Seungchan and Wang, Wenshan and Zhang, Ji and Scherer, Sebastian},
booktitle = {Proceedings of Robotics: Science and Systems (RSS)},
year = {2026}
}